
Try Engine Yard for your Rails app
START A FREE TRIALFree Download
"Top 10 Advantages of Platform-as-a-Service"
Should you DIY your app deployment & maintenance or hand it off?

Subscribe to the Engine Yard blog for expert Rails tips!
Isolation with Linux Containers
In part one of this series, we built a simple echo server, and took steps to isolate the privileges, filesystem, allocated resources, and process space. The things we did isolated the echo server process from all the other processes on the host.
In this post, we’ll look at how Linux Containers provide an easier, more powerful alternative. Instead of isolating at the process level, we’ll isolate at the OS level.
Introducing Linux Containers
Docker is the hot new thing, but Linux containers (LXC) have been around since before Docker launched in March of 2013.
The Docker FAQ cites various differences between LXC and Docker. While Docker now utilizes libcontainer, it originally wrapped the LXC user tools. In summary, LXC provided a wrapper around Linux kernel technologies, while Docker essentially provided a wrapper around LXC.
This post look at the following technologies in the context of LXC:
- Kernel namespaces
- Chroots (using pivot_root)
- uid_map and gid_map
- cgroups
- Virtual Ethernet
What Linux Containers Are Not
Linux containers are a form of isolation that may feel like virtualization. But it’s important to remember that they are not virtualization. Indeed, the performance and resource improvements gained from avoiding virtualization are why containers are superior in many situations.
Virtualization emulates the guest system, translating each and every instruction between the guest and host. A hypervisor manages this process, and there is always some sort of performance hit. Linux containers, on the other hand, share the kernel and execute instructions on the host directly. But they do share some resources, which comes with its own performance hit.
Here’s what the Linux container stack looks like:
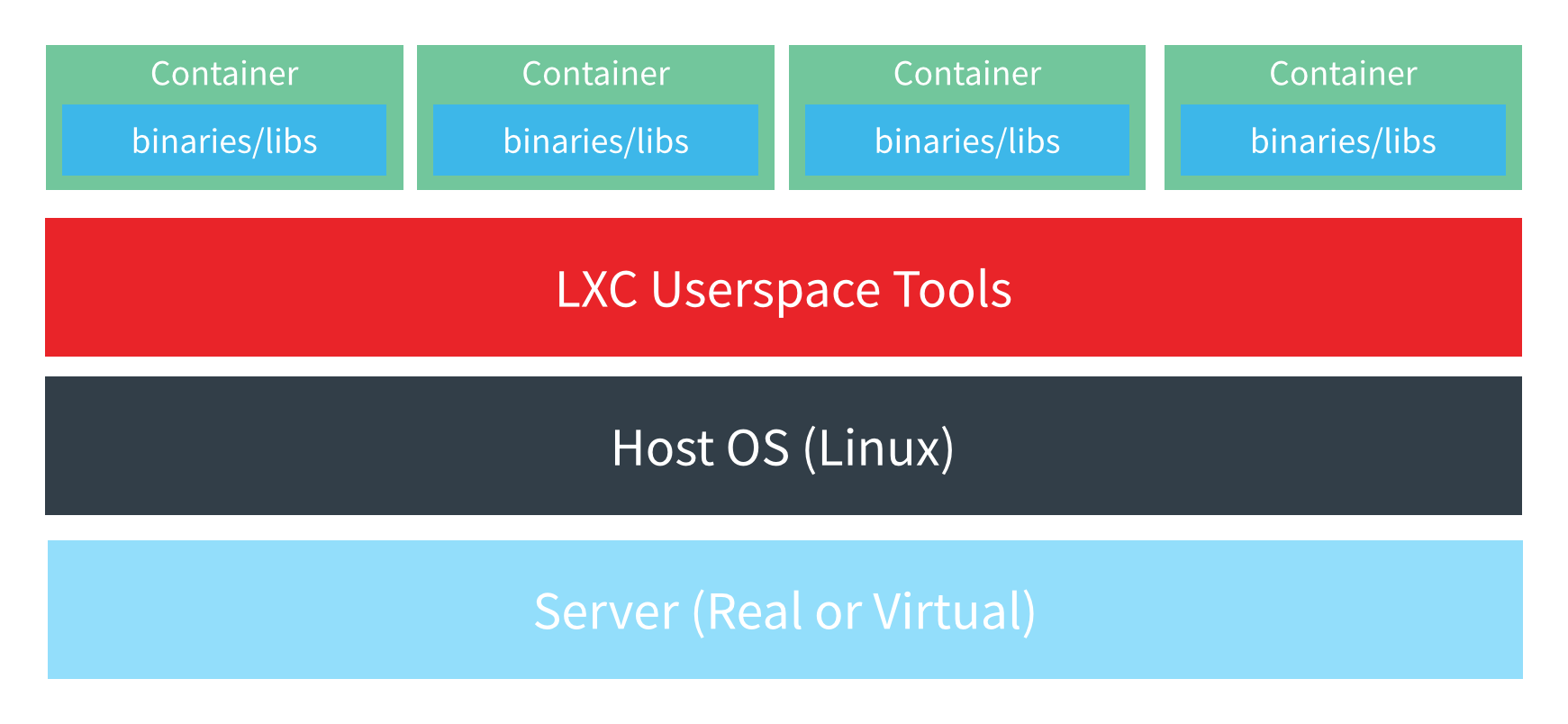
What’s the performance difference between native, container, and virtualization? Well, IBM has done some research on the issue. Their conclusions? That “containers result in equal or better performance than VM in almost all cases. “
Because Linux containers make use of the kernel directly, a Linux kernel is required for the host system. If you’re not running Linux, one common solution to this is to virtualise a Linux VM and then run LXC inside that VM. One VM, many containers.
If you need to handle more operating systems, virtualisation offers a clear advantage here. Virtualization technologies also support features such as Open Virtualization Format to more easily migrate VMs between supported systems.
Introducing pivot_root
Before diving into the specifics of LXC, let’s look at one more isolation tool that can be used independently from the LXC tooling.
Part one of this series introduced chroot, which changes the working root directory of a process and all subprocesses. We can take another approach, however. We can copy an entire root filesystem to a new location and set the root there. This is pivot_root.
The pivot_root does the following:
- Let’s you specify an old and new root directory
- Copy the files from the old root directory into the new root directory
- Make the new root directory the current root
This leaves the old root untouched, should any files need to be accessed.
If we do this, the container file system will be a (close) image of the native system. However, since we want to functionally duplicate the root without affecting the host system (and it’s mount points) in any way, we need mount point isolation. That’s where Kernel namespaces (introduced in the previous post) come in handy.
A mount namespace let’s us isolate mount information from the host system. Using this, a specific process and all subprocesses spawned from it will have their their mount related operations isolated. Since the remounting of / is one of the pivot_root operations, we need to do this so as not to modify the host system’s mount points in the process.
So actually, we have four steps here:
- Use unshare or clone system calls to create a new mount namespace and prevent the upcoming pivot_root from affecting the main system
- Take in an old and new root directory
- Copy the files from the old root directory into the new root directory
- Make the new root directory the current root (thanks to the mount namespace, this is isolated to the unshare/clone’d process)
Basic Environment Requirements
For this post, we’ll use Ubuntu 14.04 to set up LXC. A lot of effort has been put into making LXC well supported on Ubuntu. This means the difficult pieces such as kernel configuration and userspace tool setup are much easier.
For other distros, the lxc-checkconfig command can be used to verify that various kernel parameters are setup.
Here’s what it looks like:
# lxc-checkconfig
Kernel configuration not found at /proc/config.gz; searching...
Kernel configuration found at /boot/config-3.13.0-48-generic
--- Namespaces ---
Namespaces: enabled
Utsname namespace: enabled
Ipc namespace: enabled
Pid namespace: enabled
User namespace: enabled
Network namespace: enabled
Multiple /dev/pts instances: enabled
...
As for the userspace tools distributed outside of Ubuntu, it’s best to check the respective repositories for official packages. Note that cgmanager, which is used for easier cgroup management, may or may not be an LXC dependency.
For any issues that may come up during setup and creation please refer to the LXC Github Issue Tracker or the LXC mailing lists. There is also the #lxcontainers IRC channel.
LXC Tools
The LXC tools are used to interact on the userspace level with the various kernel related technologies. These tools are generally available on most popular distros. Official PPA repositories are available on the LXC downloads page.
Here, we’re using the Ubuntu Long Term Support (LTS) release:
$ sudo add-apt-repository ppa:ubuntu-lxc/lxc-lts
This PPA contains the latest long term support release of LXC as well as the latest stable version of any of its dependencies.
More info: https://launchpad.net/~ubuntu-lxc/+archive/ubuntu/lxc-lts
Press [ENTER] to continue or ctrl-c to cancel adding it
gpg: key 7635B973: public key "Launchpad PPA for Ubuntu LXC team" imported
gpg: Total number processed: 1
gpg: imported: 1 (RSA: 1)
OK
Next, LXC is installed:
$ sudo apt-get install lxc
Reading package lists... Done
Building dependency tree
Reading state information... Done
...
Setting up lxc (1.0.7-0ubuntu0.1) ...
lxc start/running
Setting up lxc dnsmasq configuration.
...
Now we have the lxc package is configured, it’s time to look into some of the underlying technologies it utilizes to get the system set up for running containers.
Linux Containers and cgroups
Recall that cgroups (mentioned in part one) are a way to manage system resources. As with many things on Linux, they are managed via the filesystem. In particular, cgroups are managed through a series of directory structures. This lets you have user owned cgroups, providing even more isolation for the container.
Installing lxc brings with it cgmanager as a dependency. This tool is used by LXC to ease the pain of interacting with cgroups directly. Additionally, it integrates with systemd to create user owned cgroups on login.
Restart the systemd logind service after installing lxc to get this functionality:
# restart systemd-logind
systemd-logind start/running, process 11098
Since the backend for allowing the subuid and guid population happens through a PAM module, those logging in over SSH should make sure that UsePAM is set to yes in the host sshd_config for this population to occur.
User Setup
In shadow 4.2, support was added for gid_map and uid_map functionality.
Here’s an example map:
$ cat /proc/9159/uid_map
0 165536 65536
The first number is the starting user ID (or for gid_map, group ID) for the process in question.
Next is the starting user ID to be utilized on the host system. If there is no host equivalent ID for the container ID there would be no way, for example, to properly tell user ID 0 on the host from that of the container’s user ID 0, as seen from the host. Naturally, IDs used by the mapping will no longer be usable by the host system.
Finally, 65536 is the limit as to the amount of user IDs that can be created. So IDs 0-65536, for mapped process, will be mapped to IDs 165536-231072 on the host.
When the process utilizing a map (in the case of containers, the root init process) or the subprocesses below it, makes any ID related system call such as getuid and getgid, the kernel will use the information in this file to return the mapped user or group ID. The user and group IDs will be consumed on the host system, in this case starting from host ID 165536. But when accessed inside the process with a uid_map or gid_map, it will instead be relative to a configured lowest user ID or group ID. This allows for the appearance of a container with user and group ID management that more closely matches a native system.
The actual creation of these maps happens through newuidmap and newgidmap. These tools, given a process ID (in this case, the container’s init process) and host to guest ID mappings, will populate the appropriate map files. Ranges are validated against the /etc/subuid and /etc/subgid files.
With that in mind, make sure those files exist:
# touch /etc/subuid
# touch /etc/subgid
Now to add an unprivileged lxc user:
# useradd -m -G users lxc
# passwd lxc
New password:
Retype new password:
passwd: password updated successfully
Unless the --configure option to turn it off was used when building shadow, valid ID ranges for the newly created user will be added to the subuid and subgid files automatically:
# grep lxc /etc/sub* 2>/dev/null
/etc/subgid:lxc:165536:65536
/etc/subuid:lxc:165536:65536
Now that user and groups are set up along with their valid subuid and subgid ranges, the LXC userspace tools need to be configured. We’ll do that by copying over a default config file and then modifying it.
Run all of the following commands as the lxc user by running this first:
# su - lxc
$
Now to create the proper directories and copy over the config:
$ mkdir -pv ~/.config/lxc
mkdir: created directory ‘/home/lxc/.config’
mkdir: created directory ‘/home/lxc/.config/lxc’
$ cp /etc/lxc/default.conf ~/.config/lxc/default.conf
Note that if this is installed into /usr/local, then the path would be /usr/local/etc/lxc/default.conf instead.
Now configure the range of user and group IDs:
$ echo 'lxc.id_map = u 0 165536 65536' >> ~/.config/lxc/default.conf
$ echo 'lxc.id_map = g 0 165536 65536' >> ~/.config/lxc/default.conf
This lets the LXC tools know what options to pass to newuidmap and newgidmap. In this case, user and group IDs of 0-65536 will be mapped starting at host ID 165536. For example, here’s the ps output of a container’s init process on the host:
# ps aux
...
165536 9159 0.0 0.0 29000 2576 ? Ss 14:18 0:00 /sbin/init
And the same process, from within the container:
# ps aux
...
root 1 0.0 0.0 33512 2888 ? Ss Jun05 0:03 /sbin/init
The host sees the user ID as 165536, but inside the container it is seen as 0, or root.
Networking Setup
Now that we’ve set up a user, we set up networking.
Users have a quota on network interfaces that can be allocated.
You can set this quota like so:
# echo 'lxc veth lxcbr0 10' >> /etc/lxc/lxc-usernet
This allocates a quota of 10 interfaces to the lxc user.
Here’s the default LXC networking config:
lxc.network.type = veth
lxc.network.link = lxcbr0
lxc.network.flags = up
lxc.network.hwaddr = 00:16:3e:xx:xx:xx
Here, veth stands for virtual ethernet, which provides a way to link containers with the host system. For unprivileged containers, this is the only supported network type. lxcbr0 is the name of the LXC network bridge, which eases packet forwarding and allows for interaction between containers. Leave this configured, as we’ll need this for our setup.
On the host, two network interfaces will be created. Both of these interfaces will start with veth and continue with an 8 character suffix. The endpoints are then connected to provide a communications tunnel. After some additional configuration, the setup could technically work as is, but the problem is that if another container was added (for example an app server container and reverse proxy container) this single communications channel would not be able to communicate with it. To get around this, the bridge is inserted between the two endpoints, as if it was all on the same network segment.
The network interface meant for the container still exists on the host though. To be properly isolated within the container, the interface needs to be moved over to the container’s network namespace. LXC handles that transparently, also renaming the interface to something more friendly, like eth0. Doing it this way, the host system is unaffected.
Unprivileged Linux Container Creation
Now that setup and configuration is done, it’s time for the actual container creation. Please note that commands for linux container management should be run as a user who is actually logged in through ssh or a login shell, instead of just simply using su to switch to that user on the host system. You have to do this so that cgmanager can be fired off by PAM login hooks to create the user owned cgroups utilized by LXC.
Run this:
$ lxc-create -t download -n my-container
Setting up the GPG keyring
Downloading the image index
---
DIST RELEASE ARCH VARIANT BUILD
---
centos 6 amd64 default 20150604_02:16
centos 6 i386 default 20150604_02:16
...
Distribution: ubuntu
Release: utopic
Architecture: amd64
Here, the amd64 Ubuntu Utopic Unicorn image was selected.
This is used to produce the container image:
Downloading the image index
Downloading the rootfs
Downloading the metadata
The image cache is now ready
Unpacking the rootfs
---
You just created an Ubuntu container (release=utopic, arch=amd64, variant=default)
To enable sshd, run: apt-get install openssh-server
For security reason, container images ship without user accounts and without a root password.
Use lxc-attach or chroot directly into the rootfs to set a root password or create user accounts.
Now you can start the newly created container:
$ lxc-start -n my-container -d
The -d option puts the process in the background. Leaving this out will start it in foreground mode, which is useful for debugging.
Use llxc-info to check the container status:
$ lxc-info -n my-container
Name: my-container
State: RUNNING
PID: 13008
IP: 10.0.3.116
CPU use: 1.07 seconds
BlkIO use: 140.00 KiB
Memory use: 6.32 MiB
KMem use: 0 bytes
Link: vethCGYNFN
TX bytes: 13.38 KiB
RX bytes: 13.45 KiB
Total bytes: 26.83 KiB
Use lxc-attach to attach to the container:
$ lxc-attach -n my-container
root@my-container:/# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 14.10
Release: 14.10
Codename: utopic
Once this is done, you can work inside the container as though you had logged in as root.
Finally containers can be stopped with:
$ lxc-stop -n my-container
And destroyed with:
$ lxc-destroy -n my-container
Conclusion
Through the use of cgroups, namespaces, ID mapping, and virtual ethernet networking, we were able to create an unprivileged Linux container that still had much of the functionality and appearance as though it were the host system itself.
This approach allows for flexible setups on a single system without the overhead of instruction emulation of virtual machines.
Some further reading:
- Linux Containers Homepage
- lxc github repository
- AppArmor and Linux Containers
- SELinux/Smack securing of LInux Containers
This only scratches the surface. There’s plenty more to cover. And of course, Docker allows us to take an even higher-level view. But more on that later.
P.S. Did you find this introduction to isolation and containers useful? What did we miss? What would you like us to cover in a subsequent post?















Share your thoughts with @engineyard on Twitter
OR
Talk about it on reddit